关注
[开源]易用的支持海量数据实时同步的超高性能分布式数据集成平台
一飞开源,介绍创意、新奇、有趣、实用的开源应用、系统、软件、硬件及技术,一个探索、发现、分享、使用与互动交流的开源技术社区平台。致力于打造活力开源社区,共建开源新生态!
一、开源项目简介
SeaTunnel 是一个非常易用的支持海量数据实时同步的超高性能分布式数据集成平台,每天可以稳定高效同步数百亿数据,已在近百家公司生产上使用。
已在滴滴、腾讯云、B 站、360、Shopee 等百家公司生产上使用。
二、开源协议
使用Apache-2.0开源协议
三、界面展示
四、功能概述
为什么我们需要 SeaTunnel
SeaTunnel 尽所能为您解决海量数据同步中可能遇到的问题:
- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
SeaTunnel 使用场景
- 海量数据同步
- 海量数据集成
- 海量数据的 ETL
- 海量数据聚合
- 多源数据处理
SeaTunnel 的特性
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 离线多源数据分析
- 高性能、海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用 SQL 做数据处理和聚合
- 支持 Spark Structured Streaming
- 支持 Spark 2.x
五、技术选型
环境依赖
- java 运行环境,java >= 8
- 如果您要在集群环境中运行 seatunnel,那么需要以下 Spark 集群环境的任意一种:
- Spark on Yarn
- Spark Standalone
如果您的数据量较小或者只是做功能验证,也可以仅使用 local 模式启动,无需集群环境,seatunnel 支持单机运行。 注: seatunnel 2.0 支持 Spark 和 Flink 上运行
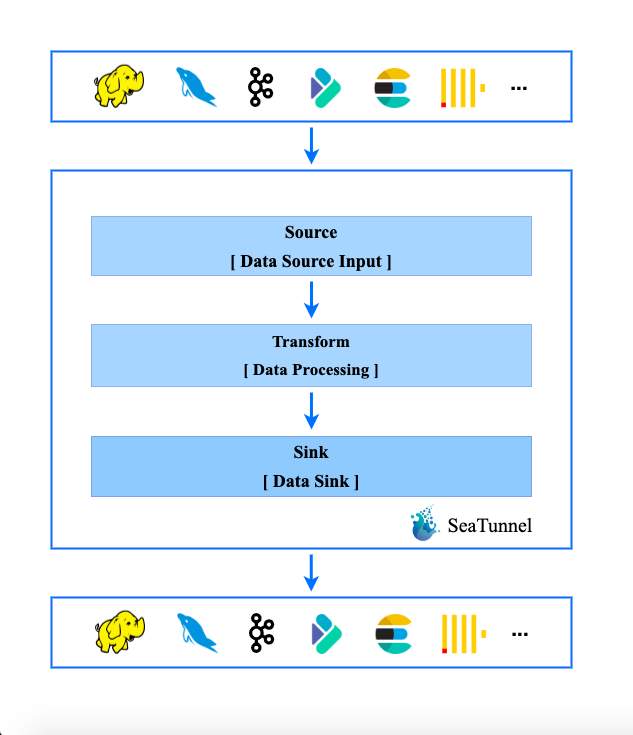
SeaTunnel 的工作流程
Source[数据源输入] -> Transform[数据处理] -> Sink[结果输出]
多个 Transform 构建了数据处理的 Pipeline,满足各种各样的数据处理需求,如果您熟悉 SQL,也可以直接通过 SQL 构建数据处理的 Pipeline,简单高效。目前 seatunnel 支持的Transform 列表, 仍然在不断扩充中。您也可以开发自己的数据处理插件,整个系统是易于扩展的。
SeaTunnel 支持的插件
- Connectors 支持
- Transform 支持
生产应用案例
- 微博, 增值业务部数据平台 微博某业务有数百个实时流式计算任务使用内部定制版 SeaTunnel,以及其子项目Guardian 做 seatunnel On Yarn 的任务监控。
- 新浪, 大数据运维分析平台 新浪运维数据分析平台使用 SeaTunnel 为新浪新闻,CDN 等服务做运维大数据的实时和离线分析,并写入 Clickhouse。
- 搜狗 ,搜狗奇点系统 搜狗奇点系统使用 SeaTunnel 作为 ETL 工具, 帮助建立实时数仓体系
- 趣头条 ,趣头条数据中心 趣头条数据中心,使用 SeaTunnel 支撑 mysql to hive 的离线 ETL 任务、实时 hive to clickhouse 的 backfill 技术支撑,很好的 cover 离线、实时大部分任务场景。
- 一下科技, 一直播数据平台
- 永辉超市子公司-永辉云创,会员电商数据分析平台 SeaTunnel 为永辉云创旗下新零售品牌永辉生活提供电商用户行为数据实时流式与离线 SQL 计算。
- 水滴筹, 数据平台 水滴筹在 Yarn 上使用 SeaTunnel 做实时流式以及定时的离线批处理,每天处理 3~4T 的数据量,最终将数据写入 Clickhouse。
六、源码地址
相关推荐


评论