关注
[开源]Java真正智慧的ORM框架,兼具Hibernate、MyBatis双重优点
一飞开源,介绍创意、新奇、有趣、实用的开源应用、系统、软件、硬件及技术,一个探索、发现、分享、使用与互动交流的开源技术社区平台。致力于打造活力开源社区,共建开源新生态!
一、开源项目简介
sqltoy-orm是什么
sqltoy-orm是比hibernate+myBatis(plus)更加贴合项目的orm框架(依赖spring),具有jpa式的对象CRUD的同时具有比myBatis(plus)更直观简洁性能强大的查询功能,越复杂优势越凸显。支持以下数据库:
- oracle11g+、db2(9.5+)、sqlserver2012+、postgresql9.5+、mysql5.6+(mariadb/innosql)
- sqlite、H2
- DM达梦数据库、kingbase
- elasticsearch 只支持查询,版本支持5.7+版本,建议使用7.3以上版本
- clickhouse、StarRocks、greenplum、impala(kudu)
- oceanBase、polardb、guassdb、tidb
- mongodb (只支持查询)
- 其他数据库支持基于jdbc的sql执行(查询和自定义sql的执行)
二、开源协议
使用Apache-2.0开源协议
三、界面展示
技术架构
架构原则:sqltoy-orm是协助开发者的工具之一,目标是要解决99.5%的问题而不是覆盖100%的问题(目前从复杂的ERP项目、数据分析报表项目的实践角度看基本100%覆盖)。
四、功能概述
Java真正智慧的ORM框架!支持mysql、oracle、postgresql、sqlserver、db2、dm、mongodb、elasticsearch、tidb、kingbase、oceanbase、guassdb、greenplum、StarRocks、impala(kudu)、clickhouse、sqlite、h2、polardb。
sqltoy-orm是基于java语言开发的,兼有hibernate面向对象操作和myBatis灵活查询的优点,同时更贴切项目、更贴切开发者的一个关系型数据库ORM框架,支持oracle、mysql、postgresql、sqlserver、db2、sqlite、sybase iq、elasticsearch、mongodb等数据库。
与sqltoy-orm配套的有一个quickvo工具,协助通过数据库表产生POJO对象类。Quickvo工具摈弃了hibernate-tools工具的不足(如模块化配置、主键策略配置、级联加载、修改、删除的逻辑),可以让开发者通过配置文件进行灵活控制POJO的生成,而不用担心自己对POJO类的修改被覆盖。
sqltoy最大的特点在于贴切项目、了解开发者,试图实实在在的帮助开发者简化数据库交互过程中的大量看似很重要其实是机械的重复工作,同时sqltoy将大量第一手项目最佳实践模式抽象成工具带给开发者。
sqltoy究竟能给你带来什么?
- 有别于hibernate的增删改(含批量和级联)内部实现,hibernate修改对象个别属性是不是要先load后修改防止其他字段被置为null?高并发大集群下面就会冲掉别人修改的数据。
- 堪称最为优雅的动态sql查询写法,一眼就可以看明白sql的业务含义,后期维护更容易,更容易进行sql优化和调整。
- 提供快速分页查询可能实现先分页后关联,减少关联数据规模。
- 让你极大减少表关联、让sql更简洁清晰并提升性能的缓存翻译功能。
- 让你不需要太牛的sql能力实现行转列、列转行。
- 提供多重分组汇总求平均的功能(算法和sql的结合,以强补弱,简单而优雅)
- 让分页查询可以只需1.45次,你的分页是不是2次查询(一次查总记录数、一次查实际记录)?
- 支持并行查询特性(4.17.13版本支持并行分页查询)
- 提供分库分表sharding功能,为高性能、分布式场景奠定基础。
- 最大程度实现跨数据库能力,提供不同数据库函数动态替换,尤其针对软件产品一个sql就可以适应不同数据库。
- Sql语句支持注释,即客户端调试好即可copy进来。机理是加载sql时剔除注释,但会保留/*+--hint--*/形式的数据库自身优化性注释。
五、技术选型
1. 基于Java语言开发
2. 快速特点说明
2.1 对象操作跟jpa类似并有针对性加强(包括级联)
- 通过quickvo工具从数据库生成对应的POJO,引入sqlltoy自带的SqlToyLazyDao即可完成全部操作
StaffInfoVO staffInfo = new StaffInfoVO();
//保存
sqlToyLazyDao.save(staffInfo);
//删除
sqlToyLazyDao.delete(new StaffInfoVO("S2007"));
//public Long update(Serializable entity, String... forceUpdateProps);
// 这里对photo 属性进行强制修改,其他为null自动会跳过
sqlToyLazyDao.update(staffInfo, "photo");
//深度修改,不管是否null全部字段修改
sqlToyLazyDao.updateDeeply(staffInfo);
List<StaffInfoVO> staffList = new ArrayList<StaffInfoVO>();
StaffInfoVO staffInfo = new StaffInfoVO();
StaffInfoVO staffInfo1 = new StaffInfoVO();
staffList.add(staffInfo);
staffList.add(staffInfo1);
//批量保存或修改
sqlToyLazyDao.saveOrUpdateAll(staffList);
//批量保存
sqlToyLazyDao.saveAll(staffList);
...............
sqlToyLazyDao.loadByIds(StaffInfoVO.class,"S2007")
//唯一性验证
sqlToyLazyDao.isUnique(staffInfo, "staffCode");
2.2 支持代码中对象查询
- sqltoy 中统一的规则是代码中可以直接传sql也可以是对应xml文件中的sqlId
/** * @todo 通过对象传参数,简化paramName[],paramValue[] 模式传参 * @param <T> * @param sqlOrNamedSql 可以是具体sql也可以是对应xml中的sqlId * @param entity 通过对象传参数,并按对象类型返回结果 */ public <T extends Serializable> List<T> findBySql(final String sqlOrNamedSql, final T entity);
- 基于对象单表查询,并带缓存翻译
public Page<StaffInfoVO> findStaff(Page<StaffInfoVO> pageModel, StaffInfoVO staffInfoVO) {
// sql可以直接在代码中编写,复杂sql建议在xml中定义
// 单表entity查询场景下sql字段可以写成java类的属性名称
return findPageEntity(pageModel, StaffInfoVO.class, EntityQuery.create()
.where("#[staffName like :staffName]#[and createTime>=:beginDate]#[and createTime<=:endDate]")
.values(staffInfoVO));
}
- 对象式查询后修改或删除
//演示代码中非直接sql模式设置条件模式进行记录修改
public Long updateByQuery() {
return sqlToyLazyDao.updateByQuery(StaffInfoVO.class,
EntityUpdate.create().set("createBy", "S0001")
.where("staffName like ?").values("张"));
}
//代码中非直接sql模式设置条件模式进行记录删除
sqlToyLazyDao.deleteByQuery(StaffInfoVO.class, EntityQuery.create().where("status=?").values(0));
2.3 极致朴素的sql编写方式
- sqltoy 的写法(一眼就看明白sql的本意,后面变更调整也非常便捷,copy到数据库客户端里稍做出来即可执行)
- sqltoy条件组织原理很简单: 如 #[order_id=:orderId] 等于if(:orderId<>null) sql.append(order_id=:orderId);#[]内只要有一个参数为null即剔除
- 支持多层嵌套:如 #[and t.order_id=:orderId #[and t.order_type=:orderType]]
- 条件判断保留#[@if(:param>=xx ||:param<=xx1) sql语句] 这种@if()高度灵活模式,为特殊复杂场景下提供便利
//1、 条件值处理跟具体sql分离
//2、 将条件值前置通过filters 定义的通用方法加工规整(大多数是不需要额外处理的)
<sql id="show_case">
<filters>
<!-- 参数statusAry只要包含-1(代表全部)则将statusAry设置为null不参与条件检索 -->
<eq params="statusAry" value="-1" />
</filters>
<value><![CDATA[
select *
from sqltoy_device_order_info t
where #[t.status in (:statusAry)]
#[and t.ORDER_ID=:orderId]
#[and t.ORGAN_ID in (:authedOrganIds)]
#[and t.STAFF_ID in (:staffIds)]
#[and t.TRANS_DATE>=:beginAndEndDate[0]]
#[and t.TRANS_DATE<:beginAndEndDate[1]]
]]></value>
</sql>
- 同等功能mybatis写法
<select id="show_case" resultMap="BaseResultMap">
select *
from sqltoy_device_order_info t
<where>
<if test="statusAry!=null">
and t.status in
<foreach collection="statusAry" item="status" separator="," open="(" close=")">
#{status}
</foreach>
</if>
<if test="orderId!=null">
and t.ORDER_ID=#{orderId}
</if>
<if test="authedOrganIds!=null">
and t.ORGAN_ID in
<foreach collection="authedOrganIds" item="organ_id" separator="," open="(" close=")">
#{order_id}
</foreach>
</if>
<if test="staffIds!=null">
and t.STAFF_ID in
<foreach collection="staffIds" item="staff_id" separator="," open="(" close=")">
#{staff_id}
</foreach>
</if>
<if test="beginDate!=null">
and t.TRANS_DATE>=#{beginDate}
</if>
<if test="endDate!=null">
and t.TRANS_DATE<#{endDate}
</if>
</where>
</select>
2.4 天然防止sql注入,执行过程:
- 假设sql语句如下
select *
from sqltoy_device_order_info t
where #[t.ORGAN_ID in (:authedOrganIds)]
#[and t.TRANS_DATE>=:beginDate]
#[and t.TRANS_DATE<:endDate]
- java调用过程
sqlToyLazyDao.findBySql(sql, MapKit.keys("authedOrganIds","beginDate", "endDate").values(authedOrganIdAry,beginDate,null),
DeviceOrderInfoVO.class);
- 最终执行的sql是这样的:
select *
from sqltoy_device_order_info t
where t.ORDER_ID=?
and t.ORGAN_ID in (?,?,?)
and t.TRANS_DATE>=?
- 然后通过: pst.set(index,value) 设置条件值
2.5 最为极致的分页
2.5.1 分页特点说明
- 1、快速分页:@fast() 实现先取单页数据然后再关联查询,极大提升速度。
- 2、分页优化器:page-optimize 让分页查询由两次变成1.3~1.5次(用缓存实现相同查询条件的总记录数量在一定周期内无需重复查询)
- 3、sqltoy的分页取总记录的过程不是简单的select count(1) from (原始sql);而是智能判断是否变成:select count(1) from 'from后语句', 并自动剔除最外层的order by
- 4、sqltoy支持并行查询:parallel="true",同时查询总记录数和单页数据,大幅提升性能
- 5、在极特殊情况下sqltoy分页考虑是最优化的,如:with t1 as (),t2 as @fast(select * from table1) select * from xxx 这种复杂查询的分页的处理,sqltoy的count查询会是:with t1 as () select count(1) from table1, 如果是:with t1 as @fast(select * from table1) select * from t1 ,count sql 就是:select count(1) from table1
2.5.2 分页sql示例
<!-- 快速分页和分页优化演示 -->
<sql id="sqltoy_fastPage">
<!-- 分页优化器,通过缓存实现查询条件一致的情况下在一定时间周期内缓存总记录数量,从而无需每次查询总记录数量 -->
<!-- parallel:是否并行查询总记录数和单页数据,当alive-max=1 时关闭缓存优化 -->
<!-- alive-max:最大存放多少个不同查询条件的总记录量; alive-seconds:查询条件记录量存活时长(比如120秒,超过阀值则重新查询) -->
<page-optimize parallel="true" alive-max="100" alive-seconds="120" />
<value>
<![CDATA[
select t1.*,t2.ORGAN_NAME
-- @fast() 实现先分页取10条(具体数量由pageSize确定),然后再关联
from @fast(select t.*
from sqltoy_staff_info t
where t.STATUS=1
#[and t.STAFF_NAME like :staffName]
order by t.ENTRY_DATE desc
) t1
left join sqltoy_organ_info t2 on t1.organ_id=t2.ORGAN_ID
]]>
</value>
<!-- 这里为极特殊情况下提供了自定义count-sql来实现极致性能优化 -->
<!-- <count-sql></count-sql> -->
</sql>
2.5.3 分页java代码调用
/**
* 基于对象传参数模式
*/
public void findPageByEntity() {
StaffInfoVO staffVO = new StaffInfoVO();
// 作为查询条件传参数
staffVO.setStaffName("陈");
// 使用了分页优化器
// 第一次调用:执行count 和 取记录两次查询
// 第二次调用:在特定时效范围内count将从缓存获取,只会执行取单页记录查询
Page result = sqlToyLazyDao.findPageBySql(new Page(), "sqltoy_fastPage", staffVO);
}
2.6 极为巧妙的缓存翻译,将多表关联查询尽量变成单表
- 1、 通过缓存翻译: 将代码转化为名称,避免关联查询,极大简化sql并提升查询效率
- 2、 通过缓存名称模糊匹配: 获取精准的编码作为条件,避免关联like 模糊查询
//支持对象属性注解模式进行缓存翻译
@Translate(cacheName = "dictKeyName", cacheType = "DEVICE_TYPE", keyField = "deviceType")
private String deviceTypeName;
@Translate(cacheName = "staffIdName", keyField = "staffId")
private String staffName;
<sql id="sqltoy_order_search">
<!-- 缓存翻译设备类型
cache:具体的缓存定义的名称,
cache-type:一般针对数据字典,提供一个分类条件过滤
columns:sql中的查询字段名称,可以逗号分隔对多个字段进行翻译
cache-indexs:缓存数据名称对应的列,不填则默认为第二列(从0开始,1则表示第二列),
例如缓存的数据结构是:key、name、fullName,则第三列表示全称
-->
<translate cache="dictKeyName" cache-type="DEVICE_TYPE" columns="deviceTypeName" cache-indexs="1"/>
<!-- 员工名称翻译,如果同一个缓存则可以同时对几个字段进行翻译 -->
<translate cache="staffIdName" columns="staffName,createName" />
<filters>
<!-- 反向利用缓存通过名称匹配出id用于精确查询 -->
<cache-arg cache-name="staffIdNameCache" param="staffName" alias-name="staffIds"/>
</filters>
<value>
<![CDATA[
select ORDER_ID,
DEVICE_TYPE,
DEVICE_TYPE deviceTypeName,-- 设备分类名称
STAFF_ID,
STAFF_ID staffName, -- 员工姓名
ORGAN_ID,
CREATE_BY,
CREATE_BY createName -- 创建人名称
from sqltoy_device_order_info t
where #[t.ORDER_ID=:orderId]
#[and t.STAFF_ID in (:staffIds)]
]]>
</value>
</sql>
2.7 并行查询
- 接口规范
// parallQuery 面向查询(不要用于事务操作过程中),sqltoy提供强大的方法,但是否恰当使用需要使用者做合理的判断 /** * @TODO 并行查询并返回一维List,有几个查询List中就包含几个结果对象,paramNames和paramValues是全部sql的条件参数的合集 * @param parallQueryList * @param paramNames * @param paramValues */ public <T> List<QueryResult<T>> parallQuery(List<ParallQuery> parallQueryList, String[] paramNames, Object[] paramValues);
- 使用范例
//定义参数
String[] paramNames = new String[] { "userId", "defaultRoles", "deployId", "authObjType" };
Object[] paramValues = new Object[] { userId, defaultRoles, GlobalConstants.DEPLOY_ID,
SagacityConstants.TempAuthObjType.GROUP };
// 使用并行查询同时执行2个sql,条件参数是2个查询的合集
List<QueryResult<TreeModel>> list = super.parallQuery(
Arrays.asList(
ParallQuery.create().sql("webframe_searchAllModuleMenus").resultType(TreeModel.class),
ParallQuery.create().sql("webframe_searchAllUserReports").resultType(TreeModel.class)),
paramNames, paramValues);
2.8 跨数据库支持
- 1、提供类似hibernate性质的对象操作,自动生成相应数据库的方言。
- 2、提供了常用的:分页、取top、取随机记录等查询,避免了各自不同数据库不同的写法。
- 3、提供了树形结构表的标准钻取查询方式,代替以往的递归查询,一种方式适配所有数据库。
- 4、sqltoy提供了大量基于算法的辅助实现,较大程度上用算法代替了以往的sql,实现了跨数据库
- 5、sqltoy提供了函数替换功能,比如可以让oracle的语句在mysql或sqlserver上执行(sql加载时将函数替换成了mysql的函数),较大程度上实现了代码的产品化。default:SubStr\Trim\Instr\Concat\Nvl 函数;可以参见org.sagacity.sqltoy.plugins.function.Nvl 代码实现
<!-- 跨数据库函数自动替换(非必须项),适用于跨数据库软件产品,如mysql开发,oracle部署 -->
<property name="functionConverts" value="default">
<!-- 也可以这样自行根据需要进行定义和扩展
<property name="functionConverts">
<list>
<value>org.sagacity.sqltoy.plugins.function.Nvl</value>
<value>org.sagacity.sqltoy.plugins.function.SubStr</value>
<value>org.sagacity.sqltoy.plugins.function.Now</value>
<value>org.sagacity.sqltoy.plugins.function.Length</value>
</list>
</property> -->
- 6、通过sqlId+dialect模式,可针对特定数据库写sql,sqltoy根据数据库类型获取实际执行sql,顺序为: dialect_sqlId->sqlId_dialect->sqlId, 如数据库为mysql,调用sqlId:sqltoy_showcase,则实际执行:sqltoy_showcase_mysql
<sql id="sqltoy_showcase">
<value>
<![CDATA[
select * from sqltoy_user_log t
where t.user_id=:userId
]]>
</value>
</sql>
<!-- sqlId_数据库方言(小写) -->
<sql id="sqltoy_showcase_mysql">
<value>
<![CDATA[
select * from sqltoy_user_log t
where t.user_id=:userId
]]>
</value>
</sql>
2.9 提供行列转换、分组汇总、同比环比等
- 水果销售记录表
品类销售月份销售笔数销售数量(吨)销售金额(万元)苹果2019年5月1220002400苹果2019年4月1119002600苹果2019年3月1320002500香蕉2019年5月1020002000香蕉2019年4月1224002700香蕉2019年3月1323002700
2.9.1 行转列(列转行也支持)
<!-- 行转列 --> <sql id="pivot_case"> <value> <![CDATA[ select t.fruit_name,t.order_month,t.sale_count,t.sale_quantity,t.total_amt from sqltoy_fruit_order t order by t.fruit_name ,t.order_month ]]> </value> <!-- 行转列,将order_month作为分类横向标题,从sale_count列到total_amt 三个指标旋转成行 --> <pivot start-column="sale_count" end-column="total_amt" group-columns="fruit_name" category-columns="order_month" /> </sql>
- 效果
品类2019年3月2019年4月2019年5月笔数数量总金额笔数数量总金额笔数数量总金额香蕉132300270012240027001020002000苹果132000250011190026001220002400
2.9.2 分组汇总、求平均(可任意层级)
<sql id="group_summary_case">
<value>
<![CDATA[
select t.fruit_name,t.order_month,t.sale_count,t.sale_quantity,t.total_amt
from sqltoy_fruit_order t
order by t.fruit_name ,t.order_month
]]>
</value>
<!-- reverse 是否反向 -->
<summary columns="sale_count,sale_quantity,total_amt" reverse="true">
<!-- 层级顺序保持从高到低 -->
<global sum-label="总计" label-column="fruit_name" />
<group group-column="fruit_name" sum-label="小计" label-column="fruit_name" />
</summary>
</sql>
- 效果
品类销售月份销售笔数销售数量(吨)销售金额(万元)总计
711260014900小计
3659007500苹果2019年5月1220002400苹果2019年4月1119002600苹果2019年3月1320002500小计
3567007400香蕉2019年5月1020002000香蕉2019年4月1224002700香蕉2019年3月1323002700
2.9.3 先行转列再环比计算
<!-- 列与列环比演示 -->
<sql id="cols_relative_case">
<value>
<![CDATA[
select t.fruit_name,t.order_month,t.sale_count,t.sale_amt,t.total_amt
from sqltoy_fruit_order t
order by t.fruit_name ,t.order_month
]]>
</value>
<!-- 数据旋转,行转列,将order_month 按列显示,每个月份下面有三个指标 -->
<pivot start-column="sale_count" end-column="total_amt" group-columns="fruit_name" category-columns="order_month" />
<!-- 列与列之间进行环比计算 -->
<cols-chain-relative group-size="3" relative-indexs="1,2" start-column="1" format="#.00%" />
</sql>
- 效果
品类2019年3月2019年4月2019年5月笔数数量比上月总金额比上月笔数数量比上月总金额比上月笔数数量比上月总金额比上月香蕉132300
2700
1224004.30%27000.00%102000-16.70%2000-26.00%苹果132000
2500
111900-5.10%26004.00%1220005.20%2400-7.70%
2.10 分库分表
2.10.1 查询分库分表(分库和分表策略可以同时使用)
sql参见quickstart项目:com/sqltoy/quickstart/sqltoy-quickstart.sql.xml 文件
<!-- 演示分库 -->
<sql id="qstart_db_sharding_case">
<sharding-datasource strategy="hashDataSource"
params="userId" />
<value>
<![CDATA[
select * from sqltoy_user_log t
-- userId 作为分库关键字段属于必备条件
where t.user_id=:userId
#[and t.log_date>=:beginDate]
#[and t.log_date<=:endDate]
]]>
</value>
</sql>
<!-- 演示分表 -->
<sql id="qstart_sharding_table_case">
<sharding-table tables="sqltoy_trans_info_15d"
strategy="realHisTable" params="beginDate" />
<value>
<![CDATA[
select * from sqltoy_trans_info_15d t
where t.trans_date>=:beginDate
#[and t.trans_date<=:endDate]
]]>
</value>
</sql>
2.10.2 操作分库分表(vo对象由quickvo工具自动根据数据库生成,且自定义的注解不会被覆盖)
@Sharding 在对象上通过注解来实现分库分表的策略配置
参见:com.sqltoy.quickstart.ShardingSearchTest 进行演示
package com.sqltoy.showcase.vo;
import java.time.LocalDate;
import java.time.LocalDateTime;
import org.sagacity.sqltoy.config.annotation.Sharding;
import org.sagacity.sqltoy.config.annotation.SqlToyEntity;
import org.sagacity.sqltoy.config.annotation.Strategy;
import com.sagframe.sqltoy.showcase.vo.base.AbstractUserLogVO;
/*
* db则是分库策略配置,table 则是分表策略配置,可以同时配置也可以独立配置
* 策略name要跟spring中的bean定义name一致,fields表示要以对象的哪几个字段值作为判断依据,可以一个或多个字段
* maxConcurrents:可选配置,表示最大并行数 maxWaitSeconds:可选配置,表示最大等待秒数
*/
@Sharding(db = @Strategy(name = "hashBalanceDBSharding", fields = { "userId" }),
// table = @Strategy(name = "hashBalanceSharding", fields = {"userId" }),
maxConcurrents = 10, maxWaitSeconds = 1800)
@SqlToyEntity
public class UserLogVO extends AbstractUserLogVO {
private static final long serialVersionUID = 1296922598783858512L;
/** default constructor */
public UserLogVO() {
super();
}
}
2.11 五种非数据库相关主键生成策略(可自扩展)
- 主键策略除了数据库自带的 sequence\identity 外包含以下数据库无关的主键策略。通过quickvo配置,自动生成在VO对象中。
2.11.1 shortNanoTime 22位有序安全ID,格式: 13位当前毫秒+6位纳秒+3位主机ID
2.11.2 nanoTimeId 26位有序安全ID,格式:15位:yyMMddHHmmssSSS+6位纳秒+2位(线程Id+随机数)+3位主机ID
2.11.3 uuid:32 位uuid
2.11.4 SnowflakeId 雪花算法ID
2.11.5 redisId 基于redis 来产生规则的ID主键
根据对象属性值,产生规则有序的ID,比如:订单类型为采购:P 销售:S,贸易类型:I内贸;O 外贸; 订单号生成规则为:1位订单类型+1位贸易类型+yyMMdd+3位流水(超过3位自动扩展) 最终会生成单号为:SI191120001
2.12 elastic原生查询支持
2.13 elasticsearch-sql 插件模式sql模式支持
2.14 sql文件变更自动重载,方便开发和调试
2.15 公共字段统一赋值,针对创建人、创建时间、修改人、修改时间等
2.16 提供了查询结果日期、数字格式化、安全脱敏处理,让复杂的事情变得简单
3.集成说明
3.1 参见trunk 下面的quickstart,并阅读readme.md进行上手
package com.sqltoy.quickstart;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
/**
*
* @project sqltoy-quickstart
* @description quickstart 主程序入口
* @author zhongxuchen
* @version v1.0, Date:2020年7月17日
* @modify 2020年7月17日,修改说明
*/
@SpringBootApplication
@ComponentScan(basePackages = { "com.sqltoy.config", "com.sqltoy.quickstart" })
@EnableTransactionManagement
public class SqlToyApplication {
/**
* @param args
*/
public static void main(String[] args) {
SpringApplication.run(SqlToyApplication.class, args);
}
}
3.2 application.properties sqltoy部分配置
# sqltoy config spring.sqltoy.sqlResourcesDir=classpath:com/sqltoy/quickstart spring.sqltoy.translateConfig=classpath:sqltoy-translate.xml spring.sqltoy.debug=true #spring.sqltoy.reservedWords=status,sex_type #dataSourceSelector: org.sagacity.sqltoy.plugins.datasource.impl.DefaultDataSourceSelector #spring.sqltoy.defaultDataSource=dataSource # 提供统一公共字段赋值(源码参见quickstart) spring.sqltoy.unifyFieldsHandler=com.sqltoy.plugins.SqlToyUnifyFieldsHandler #spring.sqltoy.printSqlTimeoutMillis=200000
3.3 缓存翻译的配置文件sqltoy-translate.xml
<?xml version="1.0" encoding="UTF-8"?>
<sagacity
xmlns="http://www.sagframe.com/schema/sqltoy-translate"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sagframe.com/schema/sqltoy-translate http://www.sagframe.com/schema/sqltoy/sqltoy-translate.xsd">
<!-- 缓存有默认失效时间,默认为1小时,因此只有较为频繁的缓存才需要及时检测 -->
<cache-translates>
<!-- 基于sql直接查询的方式获取缓存 -->
<sql-translate cache="dictKeyName"
datasource="dataSource">
<sql>
<![CDATA[
select t.DICT_KEY,t.DICT_NAME,t.STATUS
from SQLTOY_DICT_DETAIL t
where t.DICT_TYPE=:dictType
order by t.SHOW_INDEX
]]>
</sql>
</sql-translate>
<!-- 员工ID和姓名的缓存 -->
<sql-translate cache="staffIdName"
datasource="dataSource">
<sql>
<![CDATA[
select STAFF_ID,STAFF_NAME,STATUS
from SQLTOY_STAFF_INFO
]]>
</sql>
</sql-translate>
<!-- 机构号和机构名称的缓存 -->
<sql-translate cache="organIdName"
datasource="dataSource">
<sql>
<![CDATA[
select ORGAN_ID,ORGAN_NAME from SQLTOY_ORGAN_INFO order by SHOW_INDEX
]]>
</sql>
</sql-translate>
</cache-translates>
<!-- 缓存刷新检测,可以提供多个基于sql、service、rest服务检测 -->
<cache-update-checkers>
<!-- 基于sql的缓存更新检测 -->
<sql-increment-checker cache="organIdName"
check-frequency="60" datasource="dataSource">
<sql><![CDATA[
--#not_debug#--
select ORGAN_ID,ORGAN_NAME
from SQLTOY_ORGAN_INFO
where UPDATE_TIME >=:lastUpdateTime
]]></sql>
</sql-increment-checker>
<!-- 增量更新,检测到变化直接更新缓存 -->
<sql-increment-checker cache="staffIdName"
check-frequency="30" datasource="dataSource">
<sql><![CDATA[
--#not_debug#--
select STAFF_ID,STAFF_NAME,STATUS
from SQLTOY_STAFF_INFO
where UPDATE_TIME >=:lastUpdateTime
]]></sql>
</sql-increment-checker>
<!-- 增量更新,带有内部分类的查询结果第一列是分类 -->
<sql-increment-checker cache="dictKeyName"
check-frequency="15" has-inside-group="true" datasource="dataSource">
<sql><![CDATA[
--#not_debug#--
select t.DICT_TYPE,t.DICT_KEY,t.DICT_NAME,t.STATUS
from SQLTOY_DICT_DETAIL t
where t.UPDATE_TIME >=:lastUpdateTime
]]></sql>
</sql-increment-checker>
</cache-update-checkers>
</sagacity>
- 实际业务开发使用,直接利用SqlToyCRUDService 就可以进行常规的操作,避免简单的对象操作自己写service, 另外针对复杂逻辑则自己写service直接通过调用sqltoy提供的:SqlToyLazyDao 完成数据库交互操作!
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SqlToyApplication.class)
public class CrudCaseServiceTest {
@Autowired
private SqlToyCRUDService sqlToyCRUDService;
/**
* 创建一条员工记录
*/
@Test
public void saveStaffInfo() {
StaffInfoVO staffInfo = new StaffInfoVO();
staffInfo.setStaffId("S190715005");
staffInfo.setStaffCode("S190715005");
staffInfo.setStaffName("测试员工4");
staffInfo.setSexType("M");
staffInfo.setEmail("test3@aliyun.com");
staffInfo.setEntryDate(LocalDate.now());
staffInfo.setStatus(1);
staffInfo.setOrganId("C0001");
staffInfo.setPhoto(FileUtil.readAsBytes("classpath:/mock/staff_photo.jpg"));
staffInfo.setCountry("86");
sqlToyCRUDService.save(staffInfo);
}
}
4. sqltoy sql关键说明
4.1 sqltoy sql最简单规则#[] 对称符号
- #[] 等于if(中间语句参数是否有null)? true: 剔除#[] 整块代码,false:拿掉#[ 和 ] ,将中间的sql作为执行的一部分。
- #[] 支持嵌套,如#[t.status=:status #[and t.createDate>=:createDate]] 会先从内而外执行if(null)逻辑
- 利用filters条件值预处理实现判断null的统一,下面是sqltoy完整提供的条件过滤器和其他函数 不要被大段的说明吓一跳,99%都用不上,正常filters里面只会用到eq 和 to-date
<sql id="show_case">
<!-- 通过filters里面的逻辑将查询条件转为null,部分逻辑则对参数进行二次转换
默认条件参数为空白、空集合、空数组都转为null
parmas 表示可以用逗号写多个参数,param 表示只支持单个参数
-->
<filters>
<!-- 等于,如机构类别前端传负一就转为null不参与条件过滤 -->
<eq params="organType" value="-1" />
<!-- 条件值在某个区间则转为null -->
<between params="" start-value="0" end-value="9999" />
<!-- 将参数条件值转换为日期格式,format可以是yyyy-MM-dd这种自定义格式也可以是:
first_of_day:月的第一天;last_of_day:月的最后一天,first_of_year:年的第一天,last_of_year年的最后一天,increment-unit默认为days -->
<to-date params="" format="yyyyMMdd" increment-time="1" increment-unit="days"/>
<!-- 将参数转为数字 -->
<to-number params="" data-type="decimal" />
<!-- 将前端传过来的字符串切割成数组 -->
<split data-type="string" params="staffAuthOrgs" split-sign=","/>
<!-- 小于等于 -->
<lte params="" value="" />
<!-- 小于 -->
<lt params="" value="" />
<!-- 大于等于 -->
<gte params="" value="" />
<!-- 大于 -->
<gt params="" value="" />
<!-- 字符替换,默认根据正则表达进行全部替换,is-first为true时只替换首个 -->
<replace params="" regex="" value="" is-first="false" />
<!-- 首要参数,即当某个参数不为null时,excludes是指被排除之外的参数全部为null -->
<primary param="orderId" excludes="organIds" />
<!-- 排他性参数,当某个参数是xxx值时,将其他参数设置为特定值 -->
<exclusive param="" compare-type="eq" compare-values=""
set-params="" set-value="" />
<!-- 通过缓存进行文字模糊匹配获取精确的代码值参与精确查询 -->
<cache-arg cache-name="" cache-type="" param="" cache-mapping-indexes="" alias-name=""/>
<!-- 将数组转化成in 的参数条件并增加单引号 -->
<to-in-arg params=""/>
</filters>
<!-- 缓存翻译,可以多个,uncached-template 是针对未能匹配时显示的补充,${value} 表示显示key值,可以key=[${value}未定义 这种写法 -->
<translate cache="dictKeyName" cache-type="POST_TYPE" columns="POST_TYPE"
cache-indexs="1" uncached-template=""/>
<!-- 安全掩码:tel\姓名\地址\卡号 -->
<!--最简单用法: <secure-mask columns="" type="tel"/> -->
<secure-mask columns="" type="name" head-size="3" tail-size="4"
mask-code="*****" mask-rate="50" />
<!-- 分库策略 -->
<sharding-datasource strategy="" />
<!-- 分表策略 -->
<sharding-table tables="" strategy="" params="" />
<!-- 分页优化,缓存相同查询条件的分页总记录数量, alive-max:表示相同的一个sql保留100个不同条件查询 alive-seconds:相同的查询条件分页总记录数保留时长(单位秒) -->
<page-optimize alive-max="100" alive-seconds="600" />
<!-- 日期格式化 -->
<date-format columns="" format="yyyy-MM-dd HH:mm:ss"/>
<!-- 数字格式 -->
<number-format columns="" format=""/>
<value>
<![CDATA[
select t1.*,t2.ORGAN_NAME from
@fast(select * from sys_staff_info t
where #[t.sexType=:sexType]
#[and t.JOIN_DATE>:beginDate]
#[and t.STAFF_NAME like :staffName]
-- 是否虚拟员工@if()做逻辑判断
#[@if(:isVirtual==true||:isVirtual==0) and t.IS_VIRTUAL=1]
) t1,sys_organ_info t2
where t1.ORGAN_ID=t2.ORGAN_ID
]]>
</value>
<!-- 为极致分页提供自定义写sql -->
<count-sql><![CDATA[]]></count-sql>
<!-- 汇总和求平均,通过算法实现复杂的sql,同时可以变成数据库无关 -->
<summary columns="" radix-size="2" reverse="false" sum-site="left">
<global sum-label="" label-column="" />
<group sum-label="" label-column="" group-column="" />
</summary>
<!-- 拼接某列,mysql中等同于group_concat\oracle 中的WMSYS.WM_CONCAT功能 -->
<link sign="," column="" />
<!-- 行转列 (跟unpivot互斥),算法实现数据库无关 -->
<pivot category-columns="" group-columns="" start-column="" end-column=""
default-value="0" />
<!-- 列转行 -->
<unpivot columns="" values-as-column="" />
</sql>
5. sqltoy关键代码说明
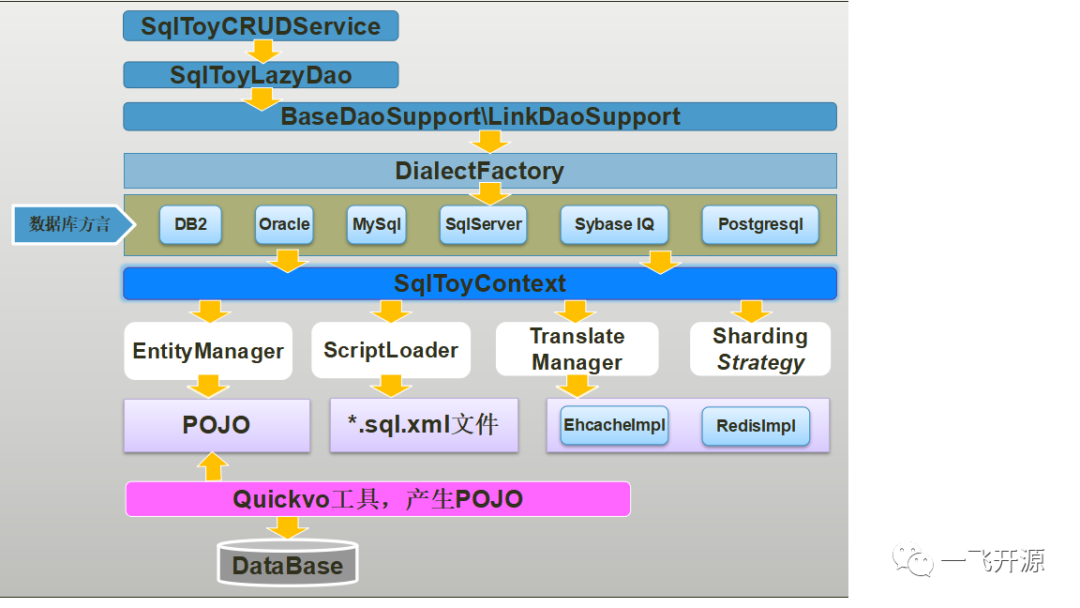
5.1 sqltoy-orm 主要分以下几个部分:
- SqlToyDaoSupport:提供给开发者Dao继承的基本Dao,集成了所有对数据库操作的方法。
- SqlToyLazyDao:提供给开发者快捷使用的Dao,让开发者只关注写Service业务逻辑代码,在service中直接调用lazyDao
- SqltoyCRUDService:简单Service的封装,面向controller层提供基于对象的快捷service调用,比如save(pojo)这种极为简单的就无需再写service代码
- DialectFactory:数据库方言工厂类,sqltoy根据当前连接的方言调用不同数据库的实现封装。
- SqlToyContext:sqltoy上下文配置,是整个框架的核心配置和交换区,spring配置主要是配置sqltoyContext。
- EntityManager:封装于SqlToyContext,用于托管POJO对象,建立对象跟数据库表的关系。sqltoy通过SqlToyEntity注解扫描加载对象。
- ScriptLoader:sql配置文件加载解析器,封装于SqlToyContext中。sql文件严格按照*.sql.xml规则命名。
- TranslateManager:缓存翻译管理器,用于加载缓存翻译的xml配置文件和缓存实现类,sqltoy提供了接口并提供了默认基于ehcache的本地缓存实现,这样效率是最高的,而redis这种分布式缓存IO开销太大,缓存翻译是一个高频度的调用,一般会缓存注入员工、机构、数据字典、产品品类、地区等相对变化不频繁的稳定数据。
- ShardingStragety:分库分表策略管理器,4.x版本之后策略管理器并不需要显式定义,只有通过spring定义,sqltoy会在使用时动态管理。
5.2 快速阅读理解sqltoy:
- 从SqlToyLazyDao作为入口,了解sqltoy提供的所有功能
- SqlToyDaoSupport 是SqlToyLazyDao 具体功能实现。
- 从DialectFactory会进入不同数据库方言的实现入口。可以跟踪看到具体数据库的实现逻辑。你会看到oracle、mysql等分页、取随机记录、快速分页的封装等。
- EntityManager:你会找到如何扫描POJO并构造成模型,知道通过POJO操作数据库实质会变成相应的sql进行交互。
- ParallelUtils:对象分库分表并行执行器,通过这个类你会看到分库分表批量操作时如何将集合分组到不同的库不同的表并进行并行调度的。
- SqlToyContext:sqltoy配置的上下文,通过这个类可以看到sqltoy全貌。
- PageOptimizeUtils:可以看到分页优化默认实现原理。
六、源码地址
相关推荐


评论